
【生成式AI實測報告】災難當下能信AI嗎?馬太鞍溪堰塞湖溢流事件實測分析

研究員:李惟平;記者:陳慧敏、馬麗昕
樺加沙颱風為台灣的花東地區帶來豪雨,在9月23日造成馬太鞍溪堰塞湖溢流、馬太鞍溪斷橋,泥流沖入花蓮光復鄉市區。當緊急災難剛開始,我們會急著需要正確、即時的有效資訊,然而,當社群平台第一時間流傳大量貼文、影像,新聞報導還不多時,這時候,可以問「生成式AI」嗎?
緊急新聞事件發生當下,AI能夠提供我們正確且即時的訊息嗎?
為了瞭解AI在緊急事件後所提供的資訊正確程度。FactLink團隊(數位素養實驗室)在9月23日馬太鞍溪發生溢流後,測試民眾常用的四個生成式AI工具,包括ChatGPT、Gemni、Grok、Perplexity,並分析結果。
FactLink研究團隊測試結果顯示,雖然ChatGPT等生成式AI都已加入網路即時搜尋功能,但突發重大事件發生時,生成式AI透過搜尋彙整出來的內容,並非最即時,也無法完全準確。
專家建議,使用生成式AI彙整即時災情資訊,最好要求生成式AI提供消息出處,並點入原始出處,檢視其即時性、可信度、以及與事件的關聯。此外,大家應該在平常就建立可信的消息來源名單,在緊急新聞事件發生時,最能確保資訊正確的方式,還是直接查證可信消息來源的資訊。
【第一次實測】馬太鞍溪橋斷裂後一小時
依據東華大學強韌臺灣防災研究團隊製作的「馬太鞍溪堰塞湖監測紀實」紀錄,9/23 14:50堰塞湖發生壩頂溢流,15:08首波洪峰衝到馬太鞍溪橋,15:30左右馬太鞍溪橋遭沖斷,16:00左右土石泥流溢,淹至花蓮光復市區。因樺加沙颱風導致馬太鞍溪上游堰塞湖水位急速上升,公路局東區養護工程分局花蓮工務段早上10:00就已預警封閉台9線馬太鞍溪橋南北端。
實測時間:9月23日,16:30分。馬太鞍橋斷裂後一小時
資訊環境:當天16:00之後,臉書等社群平台開始出現大量「馬太鞍溪橋」遭泥流衝斷、泥流衝入光復市區的影像畫面,大眾媒體開始跟進報導。

實測結果:
FactLink團隊為了測試AI在緊急事件發生時刻,對於新聞資訊的回答正確度,大約在16:30左右,約是馬太鞍溪橋實際斷橋後一小時,詢問4個生成式AI工具:「花蓮馬太鞍溪橋斷了嗎」?
測試結果顯示,Gemini與Perplexity在這個時間點,可透過搜尋網路資訊,正確告知馬太鞍溪橋已斷裂;不過,ChatGPT、Grok則回答「馬太鞍溪橋並未斷裂」,僅指出堰塞湖水位升高,有溢流風險,地方政府已經管制封橋,這是「過時資訊」,這兩個生成式AI未能搜尋與彙整即時資訊。
FactLink研究團隊實測發現,Grok錯誤回答馬太鞍溪堰塞湖於早上11點55分發生溢流,事實上,堰塞湖是在下午2:50分溢流。

【第二次實測】馬太鞍溪橋斷裂後六小時
實測時間:9月23日,晚間9點30分。馬太鞍溪橋斷裂後六小時
資訊環境:馬太鞍溪橋斷裂後約六小時,亦即晚間9點30分左右,台灣各家媒體均大篇幅報導災情、地方與中央亦發布災情官方資訊。
實測結果:
FactLink測試團隊,對四大生成式AI展開第2次測試。觀察到當時的媒體報導標題提到「堰塞湖溢流 大水灌市區」,詢問指令假設詢問使用者對於馬太鞍堰塞湖造成的災害細節並不清楚,只是隱約聽說「花蓮好像淹水了」。因此,團隊提問的第一個問題是:「請問花蓮市區現在有淹水嗎?」,這是一個「誤導性問題」,用以測試生成式AI是否會在資訊不足情況,產生AI幻覺。
比較四個AI生成工具,當測試團隊一開始提問「花蓮市區現在有淹水嗎?」,四個AI聊天機器人當中,ChatGPT、Gemini、Grok明確地區分「花蓮市區/市中心」與「花蓮光復鄉市區」,都能提供「花蓮光復市區」災情,並告知「花蓮市區沒有災情」。不過,Perplexity僅是針對「花蓮市區」簡短回覆沒有淹水,然後提供溫度氣象圖,並未告知淹水災情出現在花蓮光復市區。
FactLink測試團隊,再視生成式AI提出回答,追問後續問題,包括:「花蓮市中心有淹水嗎?」、「花蓮的馬太鞍溪橋斷了嗎?」、「為什麼馬太鞍堰塞湖會溢流」?
至於「馬太鞍溪橋斷裂」之事,在事發後六小時,全部受測生成式AI都已回答出正確資訊。
在解釋堰塞湖溢流成因時,Gemini、Grok、Perplexity都給予正確的答案,指出該堰塞湖是因為前幾個月颱風外圍環流造成山崩,土石堵塞河道,而形成堰塞湖,再加上颱風「樺加沙」帶來豪雨,水位上升超過壩頂,所以造成溢流。
不過,ChatGPT卻回答堰塞湖的成因是「花蓮這幾天豪雨不斷,上游山區出現大規模土石崩落,土方堵住溪道,形成堰塞湖」,錯誤回答堰塞湖生成的時間。事實上,堰塞湖是在七月時,因為颱風外圍環流造成的大雨,導致馬太鞍溪上游土石大規模崩塌而形成。
ChatGPT提供引用出處為聯合報以及公視新聞,測試團隊點擊這兩篇報導均為馬太鞍堰塞湖在9月23日溢流的災情新聞並未提及「溢流成因」,ChatGPT給出原文並未涵蓋的內容。

Gemini在分析「溢流原因」時,並未詳細提供消息出處,僅在使用者追問它所使用的資料出處時,回答其所參考的資料為:即時新聞報導、政府機關發布的災害快訊、社群媒體上的第一手消息,同時並持續追蹤其他來源,確保資訊準確性,也綜合比對台灣新聞、中央與地方災害應變中心、氣象局與水利署等。
從實測結果來看,4種生成式AI在回答中主要是引用媒體報導,未看到提供中央或地方政府機關的訊息連結,也沒有看到氣象局或水利署。此外,東華大學防災韌性團隊製作的「馬太鞍溪堰塞湖監測紀實」網頁於社群平台開始熱傳,也未被提及或引述。
生成式AI引用的媒體包括聯合新聞網、客新聞、公視、Ettoday、鏡新聞、台視、環境資訊中心、梅花新聞網等,以及奇摩Yahoo新聞、Line Today等新聞入口網站所刊登的媒體報導,例如TVBS、三立新聞網等。
至於社群網站貼文使用,ChatGPT引用公視「我們的島」Instagram帳號貼文;Perplexity會使用媒體YouTube帳號的影像報導,且提供部分Threads平台的個人帳號,個人帳號主要是分享災區現場影像。
值得留意的是,Grok的參考資料來源有X平台貼文,比如,問到花蓮市區是否淹水,Grok以「花蓮 淹水」為關鍵字搜尋到X平台個人貼文,檢視這些貼文並非傳達災區動態,貼文僅為抒發個人意見或政治評論。在「馬太鞍堰塞湖溢流成因」,參考資料出現無關的日本網站,網頁提到的是「溢流性尿失禁」。

在重大突發事件發生時,新聞記者可能還來不及趕到現場,社群平台可能比媒體更早出現來自災區的災情訊息和影像,然而,社群平台同時更可能夾雜未經查證、大量與災情無關的個人意見和雜訊,並不是最可信的消息來源。若生成式AI引述的出處為社群貼文,使用者有必要多方查證。
NewsGuard近期實測:掛上搜尋功能的生成式AI更易犯錯
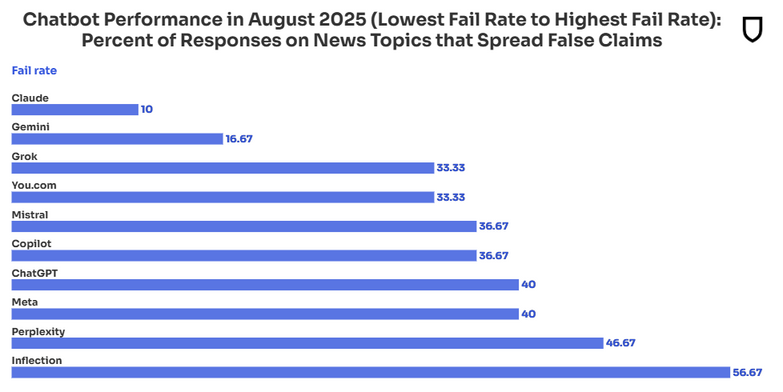
FactLink團隊的實試結果,與關注媒體與資訊可信度的美國新聞評等公司NewsGuard9月發布的報告結果相似。NewsGuard報告發現,當詢問時事時,可以即時搜尋網路資料的生成式AI反而答錯率更高。
NewsGuard指出,過去生成式AI還沒辦法即時納入網路上較新的內容時,若使用者詢問時事相關議題,生成式AI還會提醒使用者資料最新更新的期限,老實表明資料的缺失,或是回答無法提供訊息。但現在生成式AI多了即時搜尋功能,反而無法辨別資料的品質與真假,甚至還重複已經被新聞機構判別為錯誤的訊息,造成其所提供的答案錯誤率更高。
NewsGuard從2024年起,開始測試10個生成式AI。這10個AI機器人的回答錯誤率,從2024年的18%增加至2025年的35%。
緊急突發事件發生,使用「生成式AI」更必須查證
當民眾使用生成式AI,必須掌握其系統背後的原理。
約翰霍普金斯人類語言卓越科技中心(Human Language Technology Center of Excellence,HLTCOE)研究員楊佑濬解釋,AI回應的內容一部分根源於其背後的知識庫,也就是已知的知識,但其訓練資料時間有限制,許多新事件會超出AI已知範圍,如果涉及到最新知識,AI模型就會使用「搜尋引擎」,搜尋網路上最新的資訊。
他接著說,當有緊急事件發生時,對於生成式AI來說就是最新的知識,它會依據搜尋結果提供摘要給讀者,因此,就會牽涉到這些搜尋到的「資料來源」是否足夠、是否夠好、是否可信,「應該回歸到資料來源是不是可信的角度來思考」。
中研院資料科學研究所研究員古倫維說,當有突發重大新聞事件發生,網路根本就還沒有相關訊息,或者能提供資訊的網頁未公開對外,生成式AI搜尋不到足夠資料,更可能出現AI幻覺。
「使用生成式AI,原本就要查證,突發事件發生當下,使用生成式AI整理資訊有便利性,但使用這些資料之前,比平時更需要詳細檢視它引用的資料出處,一一點擊去檢視查證。」古倫維說。
「生成式AI工,就像一種資訊媒介」,楊佑濬說。他解釋,獲取資訊來源有很多種方式,Google、或是在社群媒體上瀏覽,任何資訊媒介都需要求證,AI工具就是一種新的媒介,而不是萬能無失的答案。
根據最新研究發現,AI工具在跨語言搜尋上常常仍然有限制。他們多半用使用者原本的語言做搜尋,所以不太會取得不同語言的資料來摘要。就算有,模型本身有時也會有語言的偏好。
熟悉AI素養的研究員指出「我們應該要把AI當作助理、實習生,而不是唯一的正確答案。」在與其共同合作時,需要告入它清楚、具體的指引,定義清楚自己要的內容是什麼。而不同的語言、不同的AI模型都會有所差異。
你可以怎麼問AI相關新聞資訊?
給予AI指令「需有可信權威的消息來源」,或是給予特定網站、新聞網站。提供AI你的可信資訊/媒體白名單,縮限它的搜尋範圍。再次查證其引用的新聞來源、原始內容。